


Engineering teams spend 25% of their workweek just searching for information (Atlassian State of Teams, 2026). Not building. Not shipping. Searching. PRDs live in Notion. Retros live in Confluence. Architecture decisions live in someone's head. The AI tools meant to help you plan can't read any of it, because none of it is connected.
That's not a workflow problem. It's an infrastructure problem.
Key Takeaways
- Engineering teams lose 25% of their workweek to information search alone (Atlassian, 2026).
- A Context Lake is a unified, AI-readable repository of all software knowledge, not a search index, not a knowledge base.
- Atlassian's Teamwork Graph is a feature layer on top of Jira. A Context Lake is the architectural foundation underneath planning.
- Individual AI tools boost developer output by up to 98%, yet produce zero measurable org-level productivity gain (Faros.ai, 2025).
- NexuSync's Context Lake ingests PRDs, PRs, retros, customer interviews, and commits to generate sprint-ready plans automatically.
Why Has Nobody Built the Right Planning Tool Yet?
60% of knowledge worker time goes to "work about work", status meetings, tool-switching, and chasing updates across disconnected systems (Asana Anatomy of Work, 2026). AI has made individual developers faster. It hasn't touched that 60%. The reason is structural: every AI planning tool operates on isolated inputs. It sees the ticket you're writing right now. It doesn't see the six retros that explain why your team keeps rebuilding the same feature.
Nobody built the system that coordinates AI across the full software lifecycle. That's the gap.

The Complete Guide to Continuous Planning for Software Teams
Tools exist for generating code, summarizing docs, and triaging bugs. None of them share context. None of them know that the feature you're planning this sprint was already attempted eight months ago and abandoned after two failed deployments. Your AI assistant doesn't know. Your planning tool doesn't know. Only one exhausted senior engineer remembers, and they're on leave.
The result is a team where AI makes individuals more productive while the organization spins in place. Developers ship faster. Plans still fail. Sprints still drift. 1 in 2 knowledge workers unknowingly duplicates work (Atlassian State of Teams, 2026). AI acceleration makes duplication more expensive, not less.
Where Engineering Time Goes
Bar chartWhat Is a Context Lake?
A Context Lake is a centralized, AI-readable repository that ingests every artifact from your software lifecycle, PRDs, pull requests, retrospectives, ADRs, customer interviews, Slack threads, and commit history, and structures them so that AI systems can reason across all of it when generating plans. It is not a search index. It is not a knowledge base. It's the memory layer that turns AI from a fast typist into an informed planner.
Think of it this way. A data warehouse stores business metrics for analysts to query. A knowledge base stores documents for humans to browse. A Context Lake stores structured, relational, temporally-aware software knowledge, and its primary consumer is AI, not a human with a search bar.
What a Context Lake Ingests
The inputs span the full development lifecycle:
- Strategy layer: OKRs, product briefs, roadmaps, customer interview transcripts
- Architecture layer: Architecture Decision Records (ADRs), system diagrams, dependency maps
- Execution layer: PR diffs, commit messages, CI/CD results, test coverage trends
- Team layer: Sprint retrospectives, velocity history, team capacity data
- Feedback layer: Bug reports, customer tickets, NPS data linked to features
What a Context Lake Produces
Raw ingestion isn't the point. The Context Lake enriches every artifact with metadata: who owns it, when it was created, which epics it informs, which decisions it supersedes. That enriched graph becomes the input for AI planning systems. Instead of generating a sprint plan from a blank Jira board, your AI reads six months of retros, the current product brief, and your team's velocity trends, then produces sprint-ready epics with acceptance criteria.
How It Differs from a Data Lake
A data lake stores raw, unstructured data at scale. It optimizes for storage and eventual querying by analysts. A Context Lake optimizes for AI reasoning. Every ingested artifact is parsed, chunked, tagged, and cross-referenced during ingestion. The lake is always query-ready. No transformation job runs at 2 a.m. before an AI can use it.
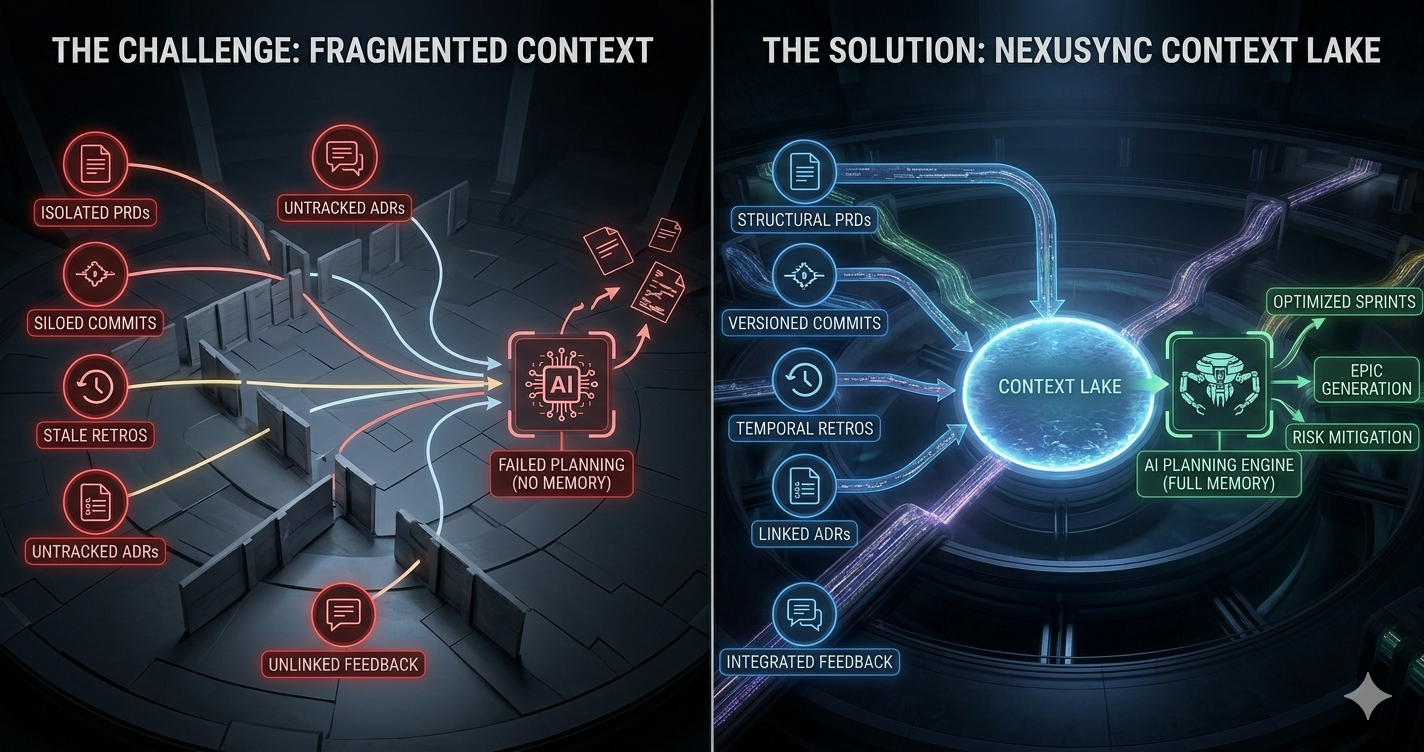
Why Can't Your Current Stack Build AI-Ready Plans?
Engineering teams spend 25% of their workweek searching for information, and 56% resort to asking colleagues directly rather than finding answers in documented systems (Atlassian State of Teams, 2026). Jira, Confluence, and Notion aren't the cause of this, they're a symptom. These tools weren't designed to feed AI. They were designed for humans to read and write. That distinction matters enormously when you want AI to plan your next sprint.
Here's the specific problem. Jira tickets are flat. Each ticket has a title, description, and status. There's no graph connecting that ticket to the customer interview that inspired it, the ADR that constrained it, or the retro that flagged a recurring pattern underneath it. Confluence pages are even worse: they're unstructured prose with no timestamps, no ownership graph, and no way for an AI to know if a page is current or three years stale.
When you ask an AI planning tool to generate a sprint from these inputs, it's reasoning in a vacuum. It doesn't know your team's velocity has dropped 30% over three sprints. It doesn't know the authentication module you're about to scope was already attempted and abandoned. It generates a plausible plan with no memory of your actual system.

Why AI Planning Tools Fail: The Missing Context Layer
The AI productivity paradox is real. Developers using AI tools complete 21% more tasks and merge 98% more pull requests, yet produce zero measurable organizational productivity gain (Faros.ai, July 2025, 10,000+ developers across 1,255 teams). Individual output goes up. System output stays flat. The missing link is shared context. AI tools help individuals work faster on the wrong things faster.
How Does a Context Lake Compare to Confluence and Jira?
| Dimension | Context Lake | Confluence / Notion | Jira / Issue Tracker | Data Lake |
|---|---|---|---|---|
| Primary purpose | AI-readable planning context | Human documentation | Task tracking | Raw data storage |
| AI readiness | Native, structured for reasoning | Low, unstructured prose | Low, flat fields, no graph | None without transformation |
| Temporal awareness | Built-in, every artifact timestamped and versioned | Manual, depends on author discipline | Partial, status history only | Depends on schema |
| Relation to code/PRs | Native, PRs, commits, and diffs are first-class | None unless manually linked | Plugin-dependent | None |
| Planning output | AI-generated epics, sprints, acceptance criteria | None | Manual, human creates from docs | None |
| Maintenance burden | Automated ingestion pipelines | High, requires human curation | Medium, teams must update tickets | High, ETL pipelines |
How Does NexuSync's Context Lake Work in Practice?
83% of Agile practitioners already use AI tools, yet 55% spend 10% or less of their working time with AI (Scrum.org, AI4Agile Practitioners Report, February 2026, n=289). The disconnect is integration depth, not tool availability. Here's what a Context Lake-driven planning flow looks like in practice, using a concrete example.
Step 1: Ingestion
A CTO uploads a new product brief for a customer-facing analytics dashboard. NexuSync ingests it alongside existing Context Lake data: eight months of sprint retros, 23 customer interview transcripts mentioning reporting features, the team's velocity trend (dropping 12% over four sprints due to technical debt), and five open ADRs related to the data layer.
The ingestion pipeline parses each artifact, extracts key entities (features, team members, technologies, decisions), and builds a cross-reference graph. No human tagging. No manual linking.
Step 2: Enrichment
The enrichment layer runs before planning. It identifies that two previous attempts to build a reporting module were closed as "too complex" after sprint three. It flags a dependency conflict between the proposed analytics service and an ADR that prohibits new direct database connections in the API layer. It notes that the team's current velocity can support four story points of net new work per sprint alongside the debt load.
This isn't retrieval. It's reasoning over your actual history.
Step 3: Planning Generation
The AI reads the enriched graph and the new product brief together. It generates a prioritized epic list, each with acceptance criteria, estimated complexity, and flagged risks. The analytics dashboard epic includes a note: "Previous attempts at this feature failed at the data aggregation layer, recommend scheduling an ADR review in Sprint 1 before committing to delivery timeline."
That's not a GPT-4 hallucination. That's a direct inference from your team's actual Context Lake.
What Gets Ingested (and What Doesn't)
Not everything belongs in a Context Lake. The value of the lake depends on signal quality, not volume. Low-quality inputs produce low-quality planning outputs. Here's the practical boundary.
Include in Your Context Lake
- Product Requirements Documents (PRDs), structured, versioned, linked to OKRs
- Architecture Decision Records (ADRs), especially when they include the alternatives considered and reasons rejected
- Pull request diffs and commit messages, with branch-to-ticket linkage
- Sprint retrospectives, structured formats only (Start/Stop/Continue or equivalent)
- Customer interview transcripts, summarized, with key themes tagged
- Team velocity history, per-sprint, per-team, broken down by work type
- Dependency maps, service graphs, team dependency matrices
- OKRs and strategy documents, with ownership and review dates
Exclude from Your Context Lake
- Raw chat logs, high noise, low signal, no structure
- Personal emails, privacy concern, low planning relevance
- Unstructured meeting notes, unless converted to a structured summary format
- Outdated documentation without version metadata, stale context is worse than no context
- Duplicate tickets, deduplication should happen at ingestion, not planning time
How Do You Build a Context Lake for Your Team?
The AI in project management market is valued at $4.28 billion in 2026 and growing to $8.9 billion by 2030 at a 19.5% CAGR (The Business Research Company, 2026). Most of that investment will go into AI features layered on top of existing tools. Teams that build a proper Context Lake now will have a structural advantage as AI planning matures. Here's how to start.
Step 1: Audit Your Existing Knowledge Sources
List every place where engineering decisions, plans, and outcomes are documented. Include: PRDs, ADRs, Confluence spaces, Notion workspaces, GitHub repositories, Slack channels used for decisions, and customer research repositories. Be honest about which sources are current and which are stale. Stale sources go on a decommission list, not the ingestion list.
Step 2: Establish Ingestion Pipelines
Connect structured, maintained sources first. GitHub is almost always ready: PR history, commit messages, and CI/CD outputs are structured by default. Sprint retrospectives in a templated format are next. Skip raw Slack. Build pipelines that check for structure before ingesting, garbage in, garbage out applies here more than anywhere.
Step 3: Define Freshness Policies
Every artifact needs a TTL (time to live) and a refresh trigger. A product brief that's 18 months old without a review date is a liability, not an asset. Set rules: ADRs expire after 12 months unless reviewed. PRDs expire when the feature ships or is canceled. Velocity data refreshes every sprint. Freshness policies keep the lake from becoming a swamp.
Step 4: Validate with Planning Output Quality
Run a controlled test. Take one upcoming sprint and generate the plan purely from Context Lake inputs, without a human facilitating. Compare the output to your team's manually generated plan from the previous sprint. Measure: How many flagged risks were ones your team would have caught? How many were surprises? How accurate were the story point estimates relative to historical velocity? Use the delta to tune your ingestion priorities.
FAQ
What's the difference between a context lake and a data lake?
A data lake stores raw, unstructured data for analyst queries. A Context Lake stores structured, AI-readable software artifacts, PRDs, ADRs, retros, PRs, optimized for planning AI to reason over, not for human analysts to query. The primary consumer is an AI system, not a BI tool or SQL query.
Does a context lake replace Confluence or Notion?
No. Confluence and Notion remain valid tools for human-authored documentation. A Context Lake ingests structured output from those tools, not the tools themselves. Teams keep writing in Notion. The Context Lake reads it, parses it, and makes it available to AI planning systems with temporal and relational metadata attached.
How does a context lake improve sprint planning?
By giving AI access to your team's full history before generating a plan. Instead of reasoning from a blank board, the AI reads sprint velocity trends, retrospective patterns, open ADRs, and customer research. Only 29% of developers trust AI-generated output today (Stack Overflow Developer Survey 2025). A Context Lake-grounded plan is auditable, every AI recommendation traces back to a specific source.
Can existing tools like Jira integrate with a context lake?
Yes, with caveats. Jira tickets can be ingested as structured records, providing status history and backlog data. But Jira alone lacks the relational depth a Context Lake needs: no customer interview linkage, no ADR cross-reference, no retrospective patterns. Jira becomes one input among many, not the source of truth it was in the old stack.
How is NexuSync's Context Lake different from Atlassian's Teamwork Graph?
Teamwork Graph is a cross-tool intelligence layer retrofitted onto Jira's existing infrastructure. It connects existing Atlassian products through inferred graph relationships. NexuSync's Context Lake is the architectural foundation, built first, with the AI planning engine designed around it. The difference is foundation vs. feature.